
在深入探討 Prometheus 的具體操作前,我們首先必須鞏固其基本概念。相信多數人第一次遇見 Prometheus,很可能是基於前輩或團隊成員的先前架構,繼承了一套現成的設定,並可能加入了某些客制化元素。在這種情況下,由於缺乏對 Prometheus 內部運作的深入理解,我們可能會猶豫不前,害怕任何小改動都可能引起不穩定。隨著時間推進,這套系統就可能變得越來越不透明,導致維護難度大增。
然而,Prometheus 其實是一個功能強大、潛力無窮的工具。只有當我們真正理解它的核心概念和運作原理,我們才能充分發揮其優勢,並信心滿滿地進行客製化。因此,接下來我將簡單介紹一些 Prometheus 中常見的關鍵詞和概念,希望能助我們深入了解它的真正能力。
Prometheus 是一套開放式原始碼的系統監控警報框架與時序資料庫(Time Series Database),其中 Prometheus 所採集的監控數據皆以指標(metric)的形式保存在本身的時序資料庫當中,這些數據按照固定的模型儲存指標,從而產生強大的查找功能。
Prometheus 的數據模型由時間序列組成。每個時間序列都由一組標籤集合( Labelsets)和其相應的指標名稱(Metrics Name)組成。這些數據點是時間戳與其對應值的組合。
形式上通過以下格式呈現:
<metric name>{<label name>=<label value>, ...}
其中以 “__” 作为前缀的標籤,是系统保留的關鍵字,只能在系统内部使用。
指標的名稱大多用來描述其所代表的功能。舉例來說,「http_requests_total」這名稱意味著「HTTP 請求的總次數」。至於「Metrics Name」,它是由 ASCII 字元、數字、英文字母、底線以及冒號構成,且必須符合 [a-zA-Z_:][a-zA-Z0-9_:]* 這樣的正規表示法規範。
通過標籤的使用,造就了 Prometheus 強大的多為數據模型,就算是相同的指標名稱,只要是不同的標籤集合,就會形成不同的維度結果。而標籤必須為符合 [a-zA-Z_][a-zA-Z0-9_]* 這樣的正規表示法規範。
時間序列基於時間戳記和相應的值來有序排列,這種序列我們通常稱之為「向量」(vector)。每一條時間序列都透過特定的指標名稱(metrics name)及其相關的標籤集合(labelset)進行識別。如果用視覺方式來解釋,時間序列可被視作一個數值矩陣,其中時間為X軸。
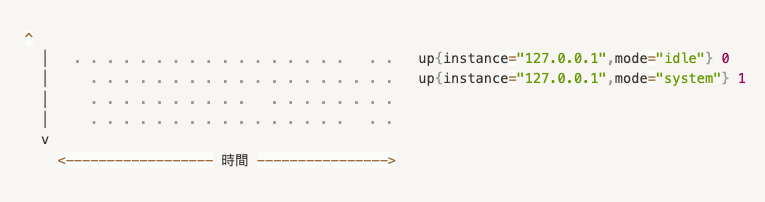
在時間序列中,每一個資料點被稱為「樣本」。每個樣本由以下三部分組成:
Prometheus 的數據模型結構使其擁有高效的存儲能力。每一筆取樣資料平均約佔3.5B,而320萬的時間序列,每30秒記錄一次,連續運作60天後,所需的磁碟空間大概是228GB。
Prometheus 在客戶端中,為我們提供了四種指標類型,但事實上這幾種指標類型概念,只存在於客戶端中,在 Prometheus 服務端中並不會特地對每一條時間序列進行區分,僅僅是簡單地將這些指標統一是為無類型的時間序列。但這些指標類型即是我們使用 PromQL 等各種客戶端函式庫工具,展現各種數據維度的關鍵所在。
為了協助使用者深入了解並分辨各式監控指標的差異,Prometheus 定義了四種獨特的指標類型:「Counter(計數器)」、「Gauge(計量器)」、「Histogram(直方圖)」和「Summary(總結)」。
Counter 類型讓人直觀地想到計數器般只增不減的特性,除非我們的監控系統發生重置,同常這種指標可以拿來表示服務請求數、已完成的任務數量、錯誤發生次數等等。
我們可以去查詢過去一個小時內的請求數,當然更多的時候我們想要看到的是請求數增加或減少的速度有多快,因此通常情況對於 Counter 指標我們都是去查看變化率而不是本身的數字。PromQL內置的聚合操作和函數可以讓用戶對這些數據進行進一步的分析,例如,通過 rate() 函數獲取HTTP 請求的增長率:
rate(http_requests_total[5m])
Gauge 可以理解為一般的數值,可大可小,這類型的指標注重於反應系統的張前狀態,例如:溫度變化、內存使用變化。當我們把 Gauge 結合先前的 Counter 類型可以呈現出:隨著 HTTP 請求數的數率變化,明顯看出 HTTP 請求數與系統記憶體之間出現一種關聯性,慢慢的我們腦中會出現一個對系統內部的運作理解。
對於 Gauge 類型指標,PromeQL 也提供內置函數像是 delta() 讓我們獲取樣本在一段時間內的差異情況。例如計算 CPU 在一分鐘內的使用量差異:
delta(cpu_usage_total{instance="127.0.0.1"}[1m])
Histogram 是一種指標類型,可以用來計算觀測值的頻率分佈。簡單來說,它可以告訴你某個值落在指定的範圍 (也稱為"bucket") 內的次數。每一個 Histogram 指標都會有一系列的 buckets,且每一次觀測會將相應的 bucket 的計數加一。
假設我們想要觀察 HTTP 請求的響應時間。可以定義以下 buckets: <50ms, <100ms, <200ms, <500ms, <1s, +Inf>。
當 Prometheus 收到一個響應時間為 120ms 的觀測值時,<200ms, <500ms, <1s, 和 +Inf 的 buckets 的計數都會增加。
Prometheus 會為 Histogram 生成以下指標:
Summary 跟 Histogram 有些相似,但它計算的是數值的百分比。對於每一次觀測,Summary 都會提供一個當前的總和和觀測的數量,這使得它可以計算出滑動時間窗口的百分位數。
假設我們想要觀測某個服務的 RPC 調用的持續時間。我們可以設定想要觀察的百分位數: 50%, 90%, 和 99%。
Prometheus 會為 Summary 生成以下指標:
當選擇 Histogram 或 Summary 時,必須事先知道想要觀察哪些範圍或百分位數。對於動態改變的數據,這是一個大挑戰。不過 Histogram 有個優勢,那就是它允許在 Prometheus 服務端進行聚合,而 Summary 則不行。
PromQL,即 Prometheus Query Language,是 Prometheus 專用的一個查詢語言,允許使用者從 Prometheus 服務端查詢時間序列數據。與傳統的數據查詢語言不同,PromQL 是專為時間序列數據而設計的,能夠支援各種豐富的數學運算以及數據聚合功能。
在 PromQL 中,用戶可以透過指定的標籤過濾和選擇所需的時間序列數據。此外,PromQL 提供了一系列的內建函數,如 rate() 和 sum(), 這使得用戶可以計算各種數據的變化率、聚合和其他高級的數據分析操作。在我們瞭解了 Prometheus 數據模型以及指標模型後,就來實際看一些 PromQL 的例子感受它的強大吧。
在 Prometheus 的查詢語言中,我們可以用四種基本的資料類型來表達我們的查詢需求,每種類型都有其特點和應用場景:
能夠從Prometheus中直接選擇時間序列:
http_requests_total{method="GET"}
查詢返回所有標籤 method 值為時間序列的最新樣本。
選擇一個時間範圍內的時間序列數據:
http_requests_total{method="GET"}[5m]
返回過去5分鐘內所有 method 值為 GET 的 http_requests_total 時間序列數據。
允許(Time Shifting)你比較當前的時間序列數據與過去的數據:
http_requests_total{method="GET"} offset 1h
這會返回1小時前的 http_requests_total 數據。
這允許用戶在某個維度上對多個時間序列進行聚合。 示例:
sum(http_requests_total) by (method)
這將所有的 http_requests_total 時間序列按 method 標籤進行分組,列出每個組進行總計。
PromQL 不僅能夠處理時間序列數據,還支援標量和字符串這兩種基本數據類型。標量是單一的數值,而字符串代表的是文字。
http_requests_total + 100
上述的例子中,100 就是一個標量。
大多數時候,我們都在處理時間序列數據。但了解這些非時間序列的基本概念,也可以幫助我們更好地理解 PromQL 的全貌。
PromQL 作為 Prometheus 的核心查詢語言,不僅僅是一個普通的監控工具的查詢語言。在其背後,它融合了許多基本的統計、數學及數據分析的觀念。這些深厚的數學基礎使得 PromQL 能夠對時間序列數據進行細緻和深入的分析。
當然,擁有這樣一個強大的工具還不夠。更重要的是,我們需要培養出一個數據分析的思維,學會從數據中提煉出真正有價值的信息。那代表著我們必需要學會看到數字背後的含義,理解它們對於系統或業務的真正影響。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day11
References
How relabeling in Prometheus works | Grafana Labs
Grafana 系列文章(十五):Exemplars - 东风微鸣 - 博客园
終於有人把Prometheus入門講明白了 | 留言送書_osc_b6tyukpz - MdEditor

 iThome鐵人賽
iThome鐵人賽